 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOMA-1M: A Large-Scale SAR-Optical Multi-resolution Alignment Dataset for Multi-Task Remote Sensing
Feb 05, 2026Synthetic Aperture Radar (SAR) and optical imagery provide complementary strengths that constitute the critical foundation for transcending single-modality constraints and facilitating cross-modal collaborative processing and intelligent interpretation. However, existing benchmark datasets often suffer from limitations such as single spatial resolution, insufficient data scale, and low alignment accuracy, making them inadequate for supporting the training and generalization of multi-scale foundation models. To address these challenges, we introduce SOMA-1M (SAR-Optical Multi-resolution Alignment), a pixel-level precisely aligned dataset containing over 1.3 million pairs of georeferenced images with a specification of 512 x 512 pixels. This dataset integrates imagery from Sentinel-1, PIESAT-1, Capella Space, and Google Earth, achieving global multi-scale coverage from 0.5 m to 10 m. It encompasses 12 typical land cover categories, effectively ensuring scene diversity and complexity. To address multimodal projection deformation and massive data registration, we designed a rigorous coarse-to-fine image matching framework ensuring pixel-level alignment. Based on this dataset, we established comprehensive evaluation benchmarks for four hierarchical vision tasks, including image matching, image fusion, SAR-assisted cloud removal, and cross-modal translation, involving over 30 mainstream algorithms. Experimental results demonstrate that supervised training on SOMA-1M significantly enhances performance across all tasks. Notably, multimodal remote sensing image (MRSI) matching performance achieves current state-of-the-art (SOTA) levels. SOMA-1M serves as a foundational resource for robust multimodal algorithms and remote sensing foundation models. The dataset will be released publicly at: https://github.com/PeihaoWu/SOMA-1M.
Accurate Network Traffic Matrix Prediction via LEAD: an LLM-Enhanced Adapter-Based Conditional Diffusion Model
Jan 29, 2026Driven by the evolution toward 6G and AI-native edge intelligence, network operations increasingly require predictive and risk-aware adaptation under stringent computation and latency constraints. Network Traffic Matrix (TM), which characterizes flow volumes between nodes, is a fundamental signal for proactive traffic engineering. However, accurate TM forecasting remains challenging due to the stochastic, non-linear, and bursty nature of network dynamics. Existing discriminative models often suffer from over-smoothing and provide limited uncertainty awareness, leading to poor fidelity under extreme bursts. To address these limitations, we propose LEAD, a Large Language Model (LLM)-Enhanced Adapter-based conditional Diffusion model. First, LEAD adopts a "Traffic-to-Image" paradigm to transform traffic matrices into RGB images, enabling global dependency modeling via vision backbones. Then, we design a "Frozen LLM with Trainable Adapter" model, which efficiently captures temporal semantics with limited computational cost. Moreover, we propose a Dual-Conditioning Strategy to precisely guide a diffusion model to generate complex, dynamic network traffic matrices. Experiments on the Abilene and GEANT datasets demonstrate that LEAD outperforms all baselines. On the Abilene dataset, LEAD attains a remarkable 45.2% reduction in RMSE against the best baseline, with the error margin rising only marginally from 0.1098 at one-step to 0.1134 at 20-step predictions. Meanwhile, on the GEANT dataset, LEAD achieves a 0.0258 RMSE at 20-step prediction horizon which is 27.3% lower than the best baseline.
TurboReg: TurboClique for Robust and Efficient Point Cloud Registration
Jul 02, 2025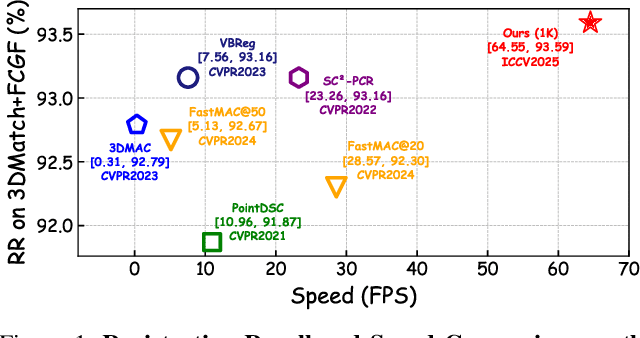



Robust estimation is essential in correspondence-based Point Cloud Registration (PCR). Existing methods using maximal clique search in compatibility graphs achieve high recall but suffer from exponential time complexity, limiting their use in time-sensitive applications. To address this challenge, we propose a fast and robust estimator, TurboReg, built upon a novel lightweight clique, TurboClique, and a highly parallelizable Pivot-Guided Search (PGS) algorithm. First, we define the TurboClique as a 3-clique within a highly-constrained compatibility graph. The lightweight nature of the 3-clique allows for efficient parallel searching, and the highly-constrained compatibility graph ensures robust spatial consistency for stable transformation estimation. Next, PGS selects matching pairs with high SC$^2$ scores as pivots, effectively guiding the search toward TurboCliques with higher inlier ratios. Moreover, the PGS algorithm has linear time complexity and is significantly more efficient than the maximal clique search with exponential time complexity. Extensive experiments show that TurboReg achieves state-of-the-art performance across multiple real-world datasets, with substantial speed improvements. For example, on the 3DMatch+FCGF dataset, TurboReg (1K) operates $208.22\times$ faster than 3DMAC while also achieving higher recall. Our code is accessible at \href{https://github.com/Laka-3DV/TurboReg}{\texttt{TurboReg}}.
Multi-Resolution SAR and Optical Remote Sensing Image Registration Methods: A Review, Datasets, and Future Perspectives
Feb 03, 2025



Synthetic Aperture Radar (SAR) and optical image registration is essential for remote sensing data fusion, with applications in military reconnaissance, environmental monitoring, and disaster management. However, challenges arise from differences in imaging mechanisms, geometric distortions, and radiometric properties between SAR and optical images. As image resolution increases, fine SAR textures become more significant, leading to alignment issues and 3D spatial discrepancies. Two major gaps exist: the lack of a publicly available multi-resolution, multi-scene registration dataset and the absence of systematic analysis of current methods. To address this, the MultiResSAR dataset was created, containing over 10k pairs of multi-source, multi-resolution, and multi-scene SAR and optical images. Sixteen state-of-the-art algorithms were tested. Results show no algorithm achieves 100% success, and performance decreases as resolution increases, with most failing on sub-meter data. XoFTR performs best among deep learning methods (40.58%), while RIFT performs best among traditional methods (66.51%). Future research should focus on noise suppression, 3D geometric fusion, cross-view transformation modeling, and deep learning optimization for robust registration of high-resolution SAR and optical images. The dataset is available at https://github.com/betterlll/Multi-Resolution-SAR-dataset-.
RANSAC Back to SOTA: A Two-stage Consensus Filtering for Real-time 3D Registration
Oct 21, 2024



Correspondence-based point cloud registration (PCR) plays a key role in robotics and computer vision. However, challenges like sensor noises, object occlusions, and descriptor limitations inevitably result in numerous outliers. RANSAC family is the most popular outlier removal solution. However, the requisite iterations escalate exponentially with the outlier ratio, rendering it far inferior to existing methods (SC2PCR [1], MAC [2], etc.) in terms of accuracy or speed. Thus, we propose a two-stage consensus filtering (TCF) that elevates RANSAC to state-of-the-art (SOTA) speed and accuracy. Firstly, one-point RANSAC obtains a consensus set based on length consistency. Subsequently, two-point RANSAC refines the set via angle consistency. Then, three-point RANSAC computes a coarse pose and removes outliers based on transformed correspondence's distances. Drawing on optimizations from one-point and two-point RANSAC, three-point RANSAC requires only a few iterations. Eventually, an iterative reweighted least squares (IRLS) is applied to yield the optimal pose. Experiments on the large-scale KITTI and ETH datasets demonstrate our method achieves up to three-orders-of-magnitude speedup compared to MAC while maintaining registration accuracy and recall. Our code is available at https://github.com/ShiPC-AI/TCF.
ML-SemReg: Boosting Point Cloud Registration with Multi-level Semantic Consistency
Jul 13, 2024



Recent advances in point cloud registration mostly leverage geometric information. Although these methods have yielded promising results, they still struggle with problems of low overlap, thus limiting their practical usage. In this paper, we propose ML-SemReg, a plug-and-play point cloud registration framework that fully exploits semantic information. Our key insight is that mismatches can be categorized into two types, i.e., inter- and intra-class, after rendering semantic clues, and can be well addressed by utilizing multi-level semantic consistency. We first propose a Group Matching module to address inter-class mismatching, outputting multiple matching groups that inherently satisfy Local Semantic Consistency. For each group, a Mask Matching module based on Scene Semantic Consistency is then introduced to suppress intra-class mismatching. Benefit from those two modules, ML-SemReg generates correspondences with a high inlier ratio. Extensive experiments demonstrate excellent performance and robustness of ML-SemReg, e.g., in hard-cases of the KITTI dataset, the Registration Recall of MAC increases by almost 34 percentage points when our ML-SemReg is equipped. Code is available at \url{https://github.com/Laka-3DV/ML-SemReg}
LiDAR-Based Place Recognition For Autonomous Driving: A Survey
Jun 18, 2023



LiDAR-based place recognition (LPR) plays a pivotal role in autonomous driving, which assists Simultaneous Localization and Mapping (SLAM) systems in reducing accumulated errors and achieving reliable localization. However, existing reviews predominantly concentrate on visual place recognition (VPR) methods. Despite notable advancements in LPR in recent years, there is yet a systematic review dedicated to this field to the best of our knowledge. This paper bridges the gap by providing a comprehensive review of place recognition methods employing LiDAR sensors, thus facilitating and encouraging further research. We commence by delving into the problem formulation of place recognition and exploring existing challenges, describing relations to previous surveys. Subsequently, we conduct an in-depth review of related research, which offers detailed classifications, strengths and weaknesses, and architectures. Finally, we summarize existing datasets, commonly used evaluation metrics, and comprehensive evaluation results from various methods on public datasets. This paper can serve as a valuable tutorial for newcomers entering the realm of place recognition and researchers interested in long-term robot localization. We pledge to maintain an up-to-date project on our website https://github.com/ShiPC-AI/LPR-Survey.
RIFT2: Speeding-up RIFT with A New Rotation-Invariance Technique
Mar 01, 2023



Multimodal image matching is an important prerequisite for multisource image information fusion. Compared with the traditional matching problem, multimodal feature matching is more challenging due to the severe nonlinear radiation distortion (NRD). Radiation-variation insensitive feature transform (RIFT)~\cite{li2019rift} has shown very good robustness to NRD and become a baseline method in multimodal feature matching. However, the high computational cost for rotation invariance largely limits its usage in practice. In this paper, we propose an improved RIFT method, called RIFT2. We develop a new rotation invariance technique based on dominant index value, which avoids the construction process of convolution sequence ring. Hence, it can speed up the running time and reduce the memory consumption of the original RIFT by almost 3 times in theory. Extensive experiments show that RIFT2 achieves similar matching performance to RIFT while being much faster and having less memory consumption. The source code will be made publicly available in \url{https://github.com/LJY-RS/RIFT2-multimodal-matching-rotation}
W-Net: Dense Semantic Segmentation of Subcutaneous Tissue in Ultrasound Images by Expanding U-Net to Incorporate Ultrasound RF Waveform Data
Sep 02, 2020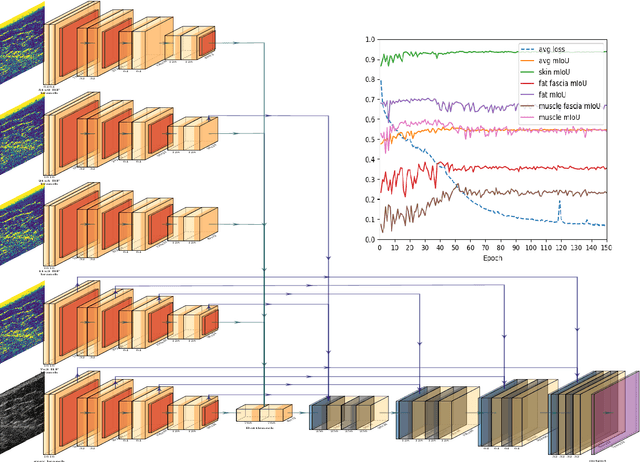

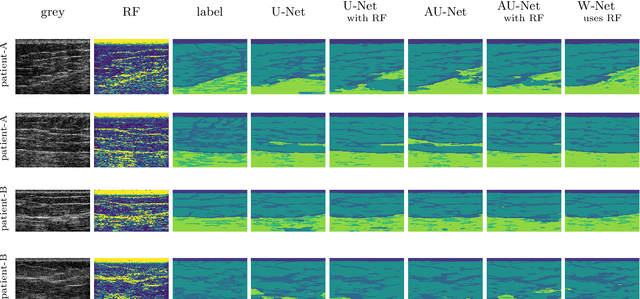
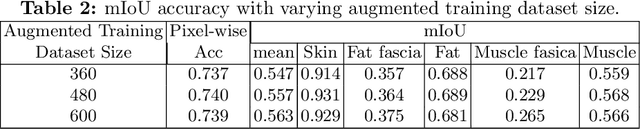
We present W-Net, a novel Convolution Neural Network (CNN) framework that employs raw ultrasound waveforms from each A-scan, typically referred to as ultrasound Radio Frequency (RF) data, in addition to the gray ultrasound image to semantically segment and label tissues. Unlike prior work, we seek to label every pixel in the image, without the use of a background class. To the best of our knowledge, this is also the first deep-learning or CNN approach for segmentation that analyses ultrasound raw RF data along with the gray image. International patent(s) pending [PCT/US20/37519]. We chose subcutaneous tissue (SubQ) segmentation as our initial clinical goal since it has diverse intermixed tissues, is challenging to segment, and is an underrepresented research area. SubQ potential applications include plastic surgery, adipose stem-cell harvesting, lymphatic monitoring, and possibly detection/treatment of certain types of tumors. A custom dataset consisting of hand-labeled images by an expert clinician and trainees are used for the experimentation, currently labeled into the following categories: skin, fat, fat fascia/stroma, muscle and muscle fascia. We compared our results with U-Net and Attention U-Net. Our novel \emph{W-Net}'s RF-Waveform input and architecture increased mIoU accuracy (averaged across all tissue classes) by 4.5\% and 4.9\% compared to regular U-Net and Attention U-Net, respectively. We present analysis as to why the Muscle fascia and Fat fascia/stroma are the most difficult tissues to label. Muscle fascia in particular, the most difficult anatomic class to recognize for both humans and AI algorithms, saw mIoU improvements of 13\% and 16\% from our W-Net vs U-Net and Attention U-Net respectively.
RIFT: Multi-modal Image Matching Based on Radiation-invariant Feature Transform
Apr 25, 2018

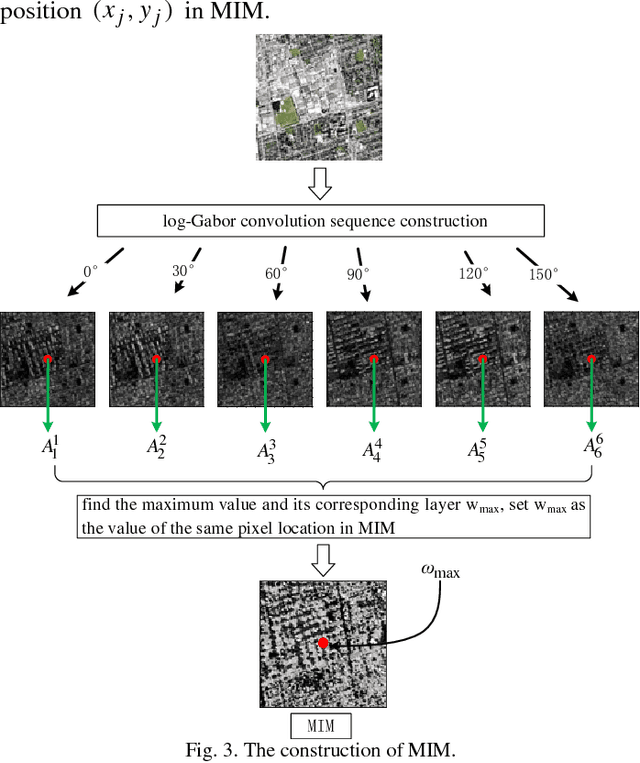

Traditional feature matching methods such as scale-invariant feature transform (SIFT) usually use image intensity or gradient information to detect and describe feature points; however, both intensity and gradient are sensitive to nonlinear radiation distortions (NRD). To solve the problem, this paper proposes a novel feature matching algorithm that is robust to large NRD. The proposed method is called radiation-invariant feature transform (RIFT). There are three main contributions in RIFT: first, RIFT uses phase congruency (PC) instead of image intensity for feature point detection. RIFT considers both the number and repeatability of feature points, and detects both corner points and edge points on the PC map. Second, RIFT originally proposes a maximum index map (MIM) for feature description. MIM is constructed from the log-Gabor convolution sequence and is much more robust to NRD than traditional gradient map. Thus, RIFT not only largely improves the stability of feature detection, but also overcomes the limitation of gradient information for feature description. Third, RIFT analyzes the inherent influence of rotations on the values of MIM, and realizes rotation invariance. We use six different types of multi-model image datasets to evaluate RIFT, including optical-optical, infrared-optical, synthetic aperture radar (SAR)-optical, depth-optical, map-optical, and day-night datasets. Experimental results show that RIFT is much more superior to SIFT and SAR-SIFT. To the best of our knowledge, RIFT is the first feature matching algorithm that can achieve good performance on all the above-mentioned types of multi-model images. The source code of RIFT and multi-modal remote sensing image datasets are made public .